
文/陈逍扬 程进 中星微人工智能芯片技术有限公司
一、引言
目前半导体器件的沟道长度接近原子直径量级,经典物理规律开始受到量子效应的影响,“More Moore”的技术演进路线已经遭遇到物理极限,并且“More-Than-Moore”在功耗、散热和厚度等方面也受到限制。芯片的发展如果没有创新的模式将无法继续按照物理定律持续前进,2018年“数字多媒体国家重点实验室”(中星微承建,以下简称“国重实验室”)首次提出智能摩尔(Intelligent Moore,i-Moore)的技术路线。它指出,虽然在物理层面和信号层面都受到物理规律的制约,看似已接近极限,但在信息层面的技术创新还远没有达到极限。下一次信息革命的关键点在于,通过进一步借鉴人脑智慧机制来研究新型人工智能计算方法,达到进一步提升信息处理的“性能/功耗价格”比的目标。
二、摩尔定律对芯片半导体发展的作用
摩尔定律是对数字集成电路和半导体工艺的技术路径进行总结和预测,经历近50年的历史检验,摩尔定律显示出惊人的准确性,其内在原因是摩尔定律本质上由经济因素驱动。由于晶体管的性能也会随着特征尺寸缩小而改善,所以随着半导体工艺制程的进化,芯片的性能也以指数级速度增长,从而带动电子产品性能大跃进式发展。因此摩尔定律不仅是一个技术上的经验规律,还成了半导体行业的发展蓝图,或者说是半导体芯片市场商业模型的重要组成部分。
1.摩尔定律由一套良性循环的“技术—市场”反馈机制来驱动和维持

图1 驱动和维持摩尔定律的反馈机制
1998年开始,由欧洲、日本、韩国、中国台湾和美国的半导体行业专家组成的ITRS(International Technology Roadmap for Semiconductors)团队每年发布一次以“More Moore”命名的半导体行业的技术路线图,供大学、公司和行业研究人员参考,刺激各个技术领域的创新。2015年起,这项工作由IRDS(International Roadmap for Devices and Systems)接手,“More Moore”路线图在器件结构、沟道材料、连接导线、高介质金属栅、架构系统、制造工艺等方面进行创新研发,有效推动了摩尔定律向前发展。
2.摩尔定律反映了集成电路的制造工艺演进路线
摩尔定律趋势图通常以MOS管沟道长度的工艺节点来表示,工艺节点数值越小,单位面积上所能放置的晶体管的数量就越多,半导体的集成度就越高。同时因为传输路径的长度减小,器件运行的速度也在加快。
微处理器40年以来的发展趋势如图2所示,可以看到摩尔定律演进规律的指数特性。然而,随着三极管尺寸缩小,这一基于CMOS开关的工艺技术路线逐渐走到了尽头,2015年斯坦福大学的Suhas Kumar提出了约束摩尔定律极限的基本条件,包括开关管热效应、量子隧道效应、散热和Compton波长约束。
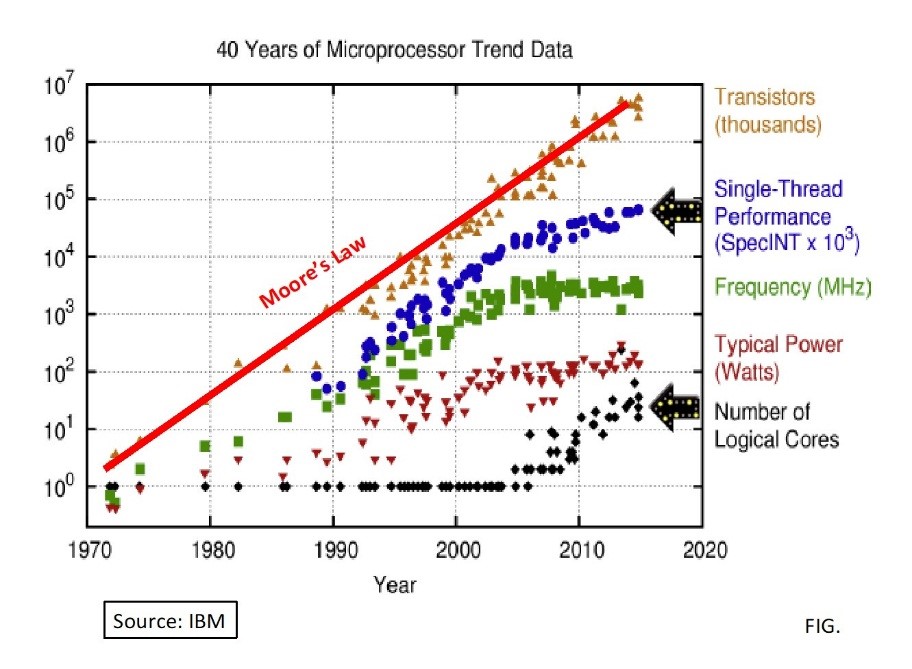
图2 40年Moore定律趋势图
3.智能摩尔之路开创新局面
在摩尔定律渐行渐止的后摩尔时代,智能摩尔技术路线为摩尔定律注入了新的活力。考虑到摩尔定律背后的市场驱动机制,当循环中的任何一个环节被打破,摩尔定律便告终止,这也正是人们对于三极管尺度不能继续减小而担心整个摩尔定律失效的根本所在。智能摩尔技术路线利用信息层面的创新,将摩尔定律中对制程工艺和封装的关注点回归到增加处理器的信息处理能力这个更基本的层次上,在循环的关键节点中注入了活力,而架构创新这一领域具有足够的深度和广度,因而可以大大延续摩尔定律的生命周期。

图3 智能摩尔技术路线:延展摩尔定律到第三个维度
三、智能摩尔技术路线下芯片计算架构得以发展
智能摩尔技术路线立足于信息处理架构的创新,它在“More Moore”和“More-Than-Moore”之外开创了一个新的创新维度,不但不会和前二者相冲突,而且能够利用前两个维度的发展进步的成果产生合力,共同作用,大幅度提高产品的整体性能。
1.信息处理架构升级凸显优势
以近年来人工智能芯片技术的发展为例,深度学习技术在智能化信息处理应用中得到了长足的发展,实践证明这种以深度神经网络作为计算架构,以大数据回归提取统计特征的技术,在实际应用中能够得到更好的分类精度和更强的泛化能力。随着深度学习算法架构的发展进步,针对深度神经网络算法和数据流设计的神经网络处理器(Neural Network Processing Unit)也应运而生。NPU颠覆了冯·诺依曼架构,采用了数据驱动、并行计算的方式,它利用深度神经网络计算中的海量数据流动、高度密集乘加运算等特点,通过优化处理器数据流通路,大量部署乘加器(MAC)单元等手段,获得比传统的CPU更高的“性能/功耗”比。
以目前最先进的第9代8核心i7处理器为例,在高达31GHz的主频和65W的能耗下,该处理器能够提供约150G FLOPS的处理能力,其效能比为23G FLOPS/W。专为深度学习开发的云端计算处理器TPUv3,通过使用了大量的MAC阵列和优化矩阵运算数据流设计,在200W的功耗下能够提供420T FLOPS的峰值计算能力,效能比高达21T FLOPS/W,比CPU提高了3个数量级。根据以上例子可有力说明,通过信息层面的计算架构创新能够带来显著优势。
2.多模融合计算架构顺势发展
虽然深度学习在图像智能处理、语音识别以及自然语言处理等领域都获得了极大成功,但是它对大数据的依赖使得其应用受限于样本数据的分布质量和获取的难度。部分应用场景中有效的样本数据极难获得或者分布严重不均衡,例如山体滑坡、地震等地质灾害前的数据等。这种小数据、小样本的场景并不适合使用深度学习技术,而适合使用基于人工设计的特征集和滤波器的模板匹配算法以及融合人类先验知识的推理模型。由此可见智能化信息处理算法必须具有多样性。
以SLAM应用为例,信号输入传感器有毫米波雷达、激光雷达、惯性和角速度传感器、GPS/北斗位置传感器、可见光和红外图像传感器等数据,其信息处理算法包括距离测定、目标识别、图像分割、定位建图等模块,这些算法需要使用传统的特征提取和目标分割,基于深度学习的神经网络推理计算、光流场计算、逻辑推理运算以及对特定数据结构的支持。由此国重实验室提出使用多模融合计算架构来应对复杂的应用场景,将深度学习算法和传统智能算法相互融合、相互比对和纠错,保障智能化信息处理系统的可靠性和可控性。
3.多核异构处理架构或将成为明日之星
单独的CPU、GPU、DSP、FPGA和NPU都无法有效地支持多模融合计算架构,因此国重实验室设计了XPU多核异构智能处理器来支持多模融合计算。XPU多核异构智能处理器(Multi-core Heterogeneous Intelligent Processor)可以在同一芯片配备NPU、DSP、CPU、GPU、FPGA以及专用的计算加速单元等不同类型的处理器核心并实现算力共享和内存共享,不同架构特点的智能算法能够在XPU处理器中实现底层、深层次的融合计算。XPU多核异构智能处理器能够在实际应用中,特别是嵌入式应用中提高系统的“性能/功耗”比,是智能摩尔技术路线的重要节点。
展望未来,中星微/国家重点实验室认为:基于智能传感的XPU和基于事件驱动的XPU是未来“智能摩尔”技术路线的两个关键技术。智能传感技术将特征点提取、光流场分析等智能化模块前置到传感器端,在优化系统的实时性的同时降低传输带宽和后级模块的运算量需求,这就是新一代分级的XPU多核异构处理器的基本原理。基于事件驱动的计算架构则是模仿人脑的分区机制和事件处理机制,在芯片中部署大量、专用、高效的PU(Processing Unit),在特定事件下能够激活特定PU。事件驱动计算能够大大降低系统能耗,这种架构的XPU被称为“分级分区的XPU多核异构处理器”。相比NPU、GPU这一类深度学习处理器,XPU多核异构智能处理器更适合目前的信息理论发展现状,在实际应用中更灵活、高效和低能耗。

图4 XPU多核异构处理器架构图
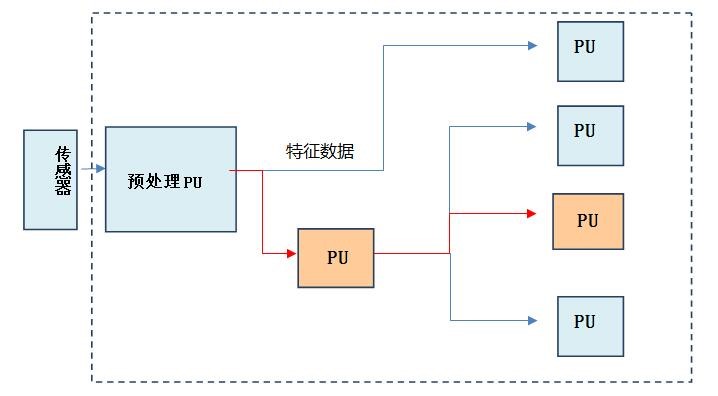
图5 分级分区XPU多核异构处理器架构示意图
四、智能摩尔发展路线助力芯片在安防行业持续前进
基于安防行业的独有属性,SVAC标准将音视频编解码技术和视频图像智能化目标检测融合起来,称为视频结构化技术。通过对原始视频进行智能分析,实时感知人、车、物、身份特征及行为,将图像智能分析结果和传感器感知的信息插入视频中一起编码,实现对视频的多元结构化描述。复杂的视频监控现场环境,对智能化处理算法提出了严苛的要求,能够将传统目标识别算法和深度学习算法进行深度融合的多模融合计算架构,能够大大提升系统在复杂多变的现场环境下准确率。XPU多核异构处理器能对这些具有不同计算特点的算法进行高效率的支持,为智能计算提供极佳的解决方案。此外、XPU多核异构处理器还具有高度集成的特性,在提供高速计算的同时满足现场的低功耗和小尺寸、低成本的需求,使得智能摄像机具有更好的“性能/功耗价格”比。
同时智能摩尔对AI芯片指出创新方向:借鉴人脑智慧机制。到目前为止人们对大脑的结构和运作机制知之甚少,仅仅是初步的认知都已经对人工智能的研究产生了极大的推动。类人脑计算(Brain Inspired Computing)这个领域具有足够的广度和深度,将会在相当长的时间内为信息科技的进步提供巨大的动力。从目前的认知来看,人脑具有以下特征:
1.大规模、低能耗及高性能。根据相关研究,成人大脑新皮质(Cerebral neocortex)约有200亿个神经元,而整个脑中估计有1000亿个神经元。人脑以约20W的功耗实现了约20 POPs神经元突触的操作,具有等效1 POPs/W的超高“性能/功耗”比。
2.分区机制。根据最新对大脑皮层脑区与皮层下核团亚区的研究,绘制出脑网络组图谱,包括246个精细脑区亚区,以及脑区亚区间的多模态连接模式。人脑的分区机制表明,相比“通用”的计算架构,针对具体算法特点而设计的“专用”计算结构可以获得更高的能效比。
3.事件驱动。研究表明,人脑所具备的高“性能/功耗”比还和事件驱动机制有关,通常一种刺激产生的“事件”,仅仅激活相关的“分区”进行处理,而其他“分区”处于极低能耗状态。
4.关联记忆以及遗忘机制。人脑具有通过反复刺激来建立“同时”或者“时序”发生的事件的能力,而较少刺激产生的记忆会被“遗忘”,这种“自学习”的机制比我们当前使用的无监督学习更加有效。
五、人工智能芯片发展新维度
对于图像类的AI芯片来说,未来的图像和视频传感器的技术发展路线呈现三个独立的维度:图像分辨率、视频的帧速以及更好的感光特性。这三个维度都和信息的传输处理息息相关。
以安防行业为例,图像的分辨率从D1(80万像素)到全高清(200万像素)只用了几年时间,目前已有800万像素级监控摄像机产品。而视频的帧速在交通、银行等行业,则需要从目前的25 FPS(Frame Per Second)到50 FPS,甚至100 FPS。与此同时,全天候和低照度的成像能力一直是视频应用的关键技术,使用10bit或者16bit的高精度数据,是提高动态范围和全天候能力的有效方法。随着传感器技术的进步,系统的信息处理能力需要同步升级,而由量变到质变的技术积累,将会导致整个技术路线的革命,对图像处理、编码压缩、传输以及存储、智能化分析等环节均提出了更高的要求。
智能传感技术将特征点提取、光流场分析等智能化模块前置到传感器端,使得每个像素都变成了“智能像素”,它不仅可以感知自身在事件维度上的变化、还可以感知和临近像素的差异以及“流动”方向(光流矢量),这样不仅大大降低了后续的智能化处理的算力要求,而且也能节省大量的传输带宽。未来的图像类的深度学习计算方法可能又将从基于像素的分析回归到基于特征的分析。
六、结语
摩尔定律依赖于制程和工艺的进步,与之不同的是智能摩尔则依赖于信息算法理论和架构的进步,相比之下复杂度远远高于前者。因此智能摩尔无法如摩尔定律一样给出每个周期的时间表和技术成果,目前人们对信息技术的认知程度尚无法掌握其外推的规律,甚至还没有能力给它定义度量单位(如工艺节点等)。但毋庸置疑的是,每一次进步都会给行业和整个社会带来极大进步。国重实验室将紧跟信息化基础理论和应用发展的步伐,以此不断深化和发展智能摩尔技术路线,为智能化信息处理提供源源不断的推力,我们相信芯片半导体技术也将在智能摩尔之路上创造无限辉煌。